Introduction – Why Availability Matters
Imagine your favourite shopping site goes down during a big sale or a multiplayer game server crashes mid-match. Those outages cost money, trust, and time. Availability is the engineering discipline that reduces those risks.
In this article you’ll learn:
- What availability is and how to measure it.
- How small changes in “nines” drastically affect downtime.
- Practical design techniques to improve availability.
- How planned and unplanned downtime differ — and how to reduce both.
Availability in System Design: Availability is one of the most crucial factors in system design. It refers to the probability that a system is operational and accessible when users need it.
The higher the availability, the more reliable the system appears to end users.
Availability Formula
Availability is generally calculated using the formula:
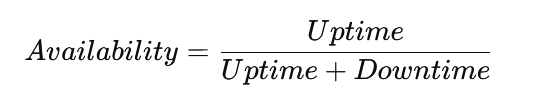
- Uptime: Time when the system performs as expected.
- Downtime: Time when the system is unavailable (due to maintenance, failures, etc.).
Example
If a system is down for 1 hour in a 30-day month:
- Hours in month = 30 × 24 = 720
- Uptime = 720 − 1 = 719
- Availability = (719 / 720) × 100 = 99.86%
Levels of Availability (“Nines”)
Small improvements in decimals significantly impact downtime.
| Availability | Downtime per Year | Common Term |
|---|---|---|
| 99% | ~3.65 days | Two nines |
| 99.9% | ~8.76 hours | Three nines |
| 99.99% | ~52 minutes | Four nines |
| 99.999% | ~5 minutes | Five nines |
Most critical systems (like banking, healthcare, stock trading) aim for four nines or higher.
Tip: Don’t pick a “five nines” target unless you need it — higher availability costs more and adds complexity.
Key Strategies to Achieve High Availability
Below are practical, easy-to-understand techniques used in production systems.
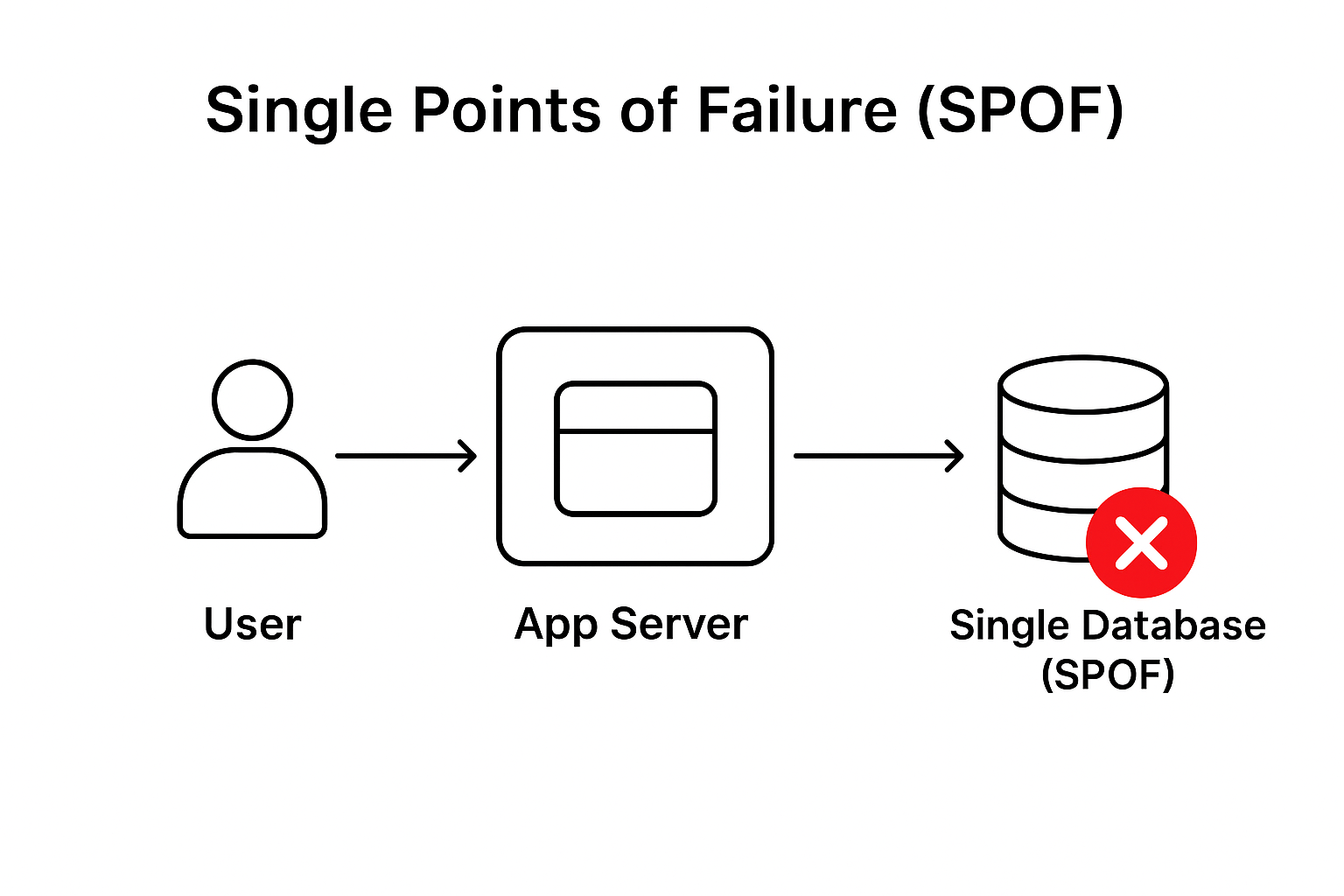
1. Eliminate Single Points of Failure (SPOF)
- Replace single servers with multiple servers.
- Add redundancy at every layer (frontend, app, database, network).
Mini example: If your only database instance fails, all users are impacted. A primary + replica setup avoids that.
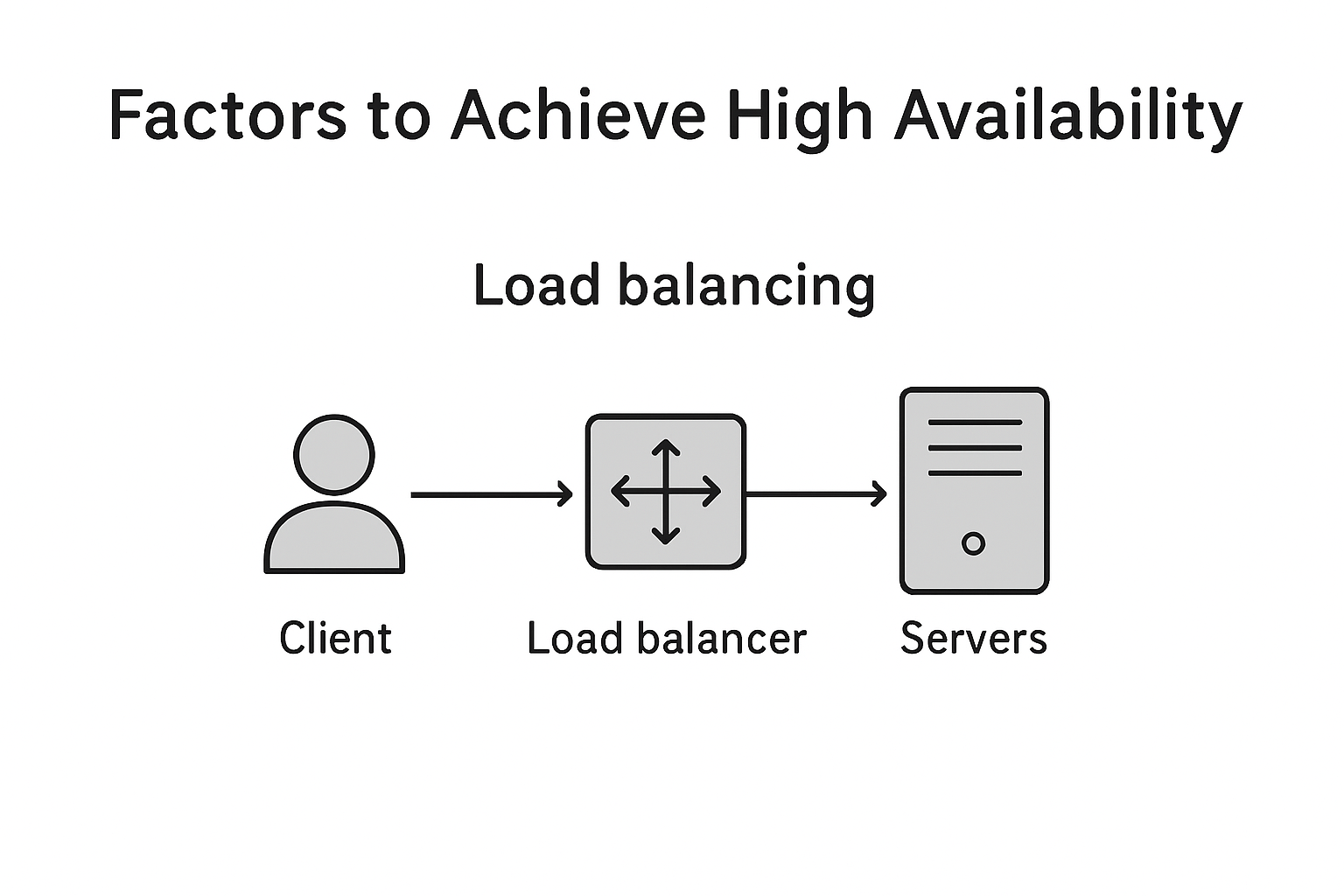
2. Load Balancing
- Distributes incoming traffic across multiple servers to avoid overload and hide node failures.
- Common options: AWS ELB, GCP Load Balancer, NGINX.
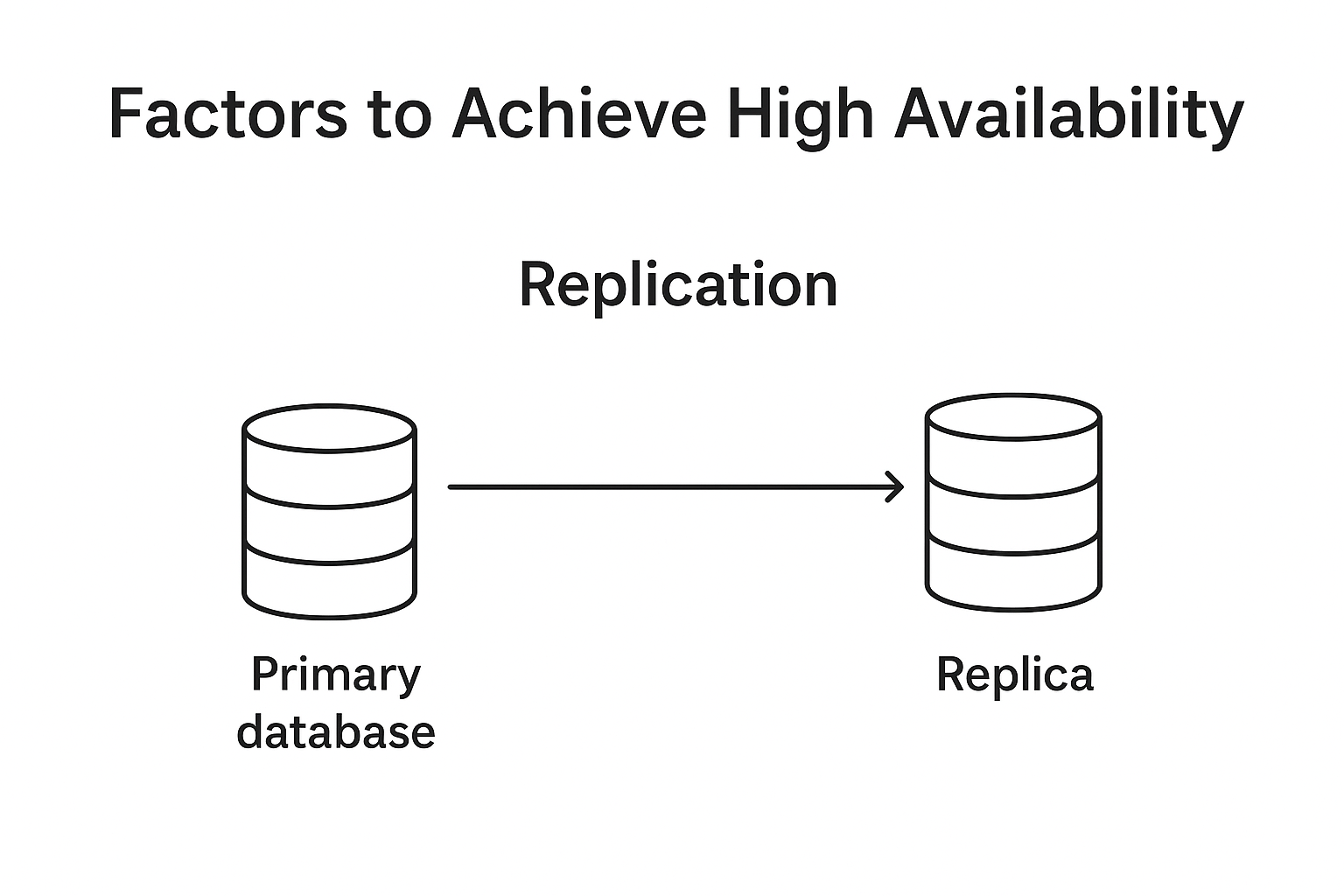
3. Replication
- Keep multiple copies of data across nodes so a replica can serve when primary fails.
- Typical modes: master-slave (primary + read replicas) and master-master (bi-directional).
Caution: Multi-master simplifies availability but adds conflict resolution complexity.
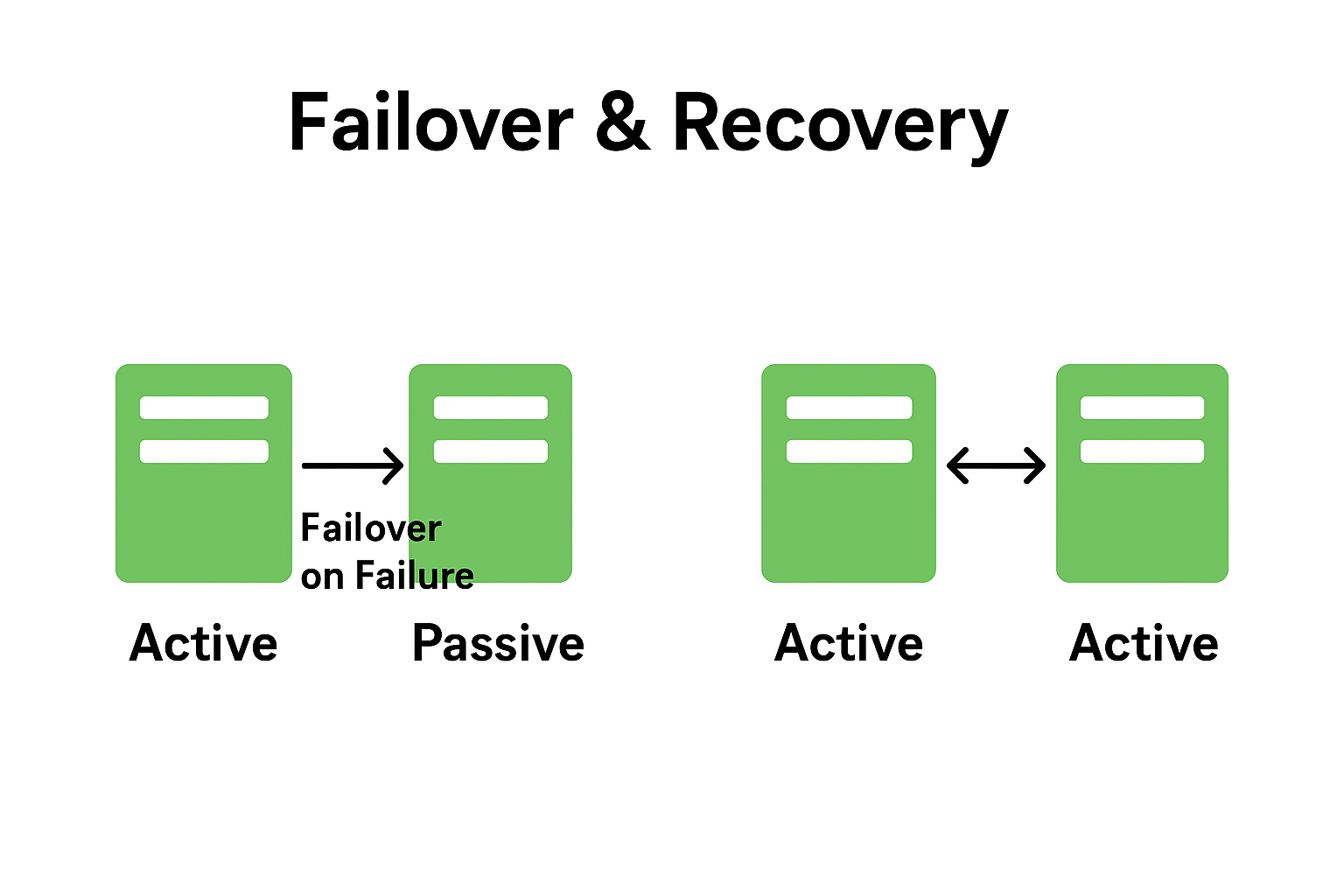
4. Failover & Recovery
- Automatically switch to backup systems when the primary fails.
Types:
- Active-Passive: One active instance, backups hot/standby.
- Active-Active: All instances serve traffic and share load.
Note: Active-active reduces downtime but requires careful data consistency management.
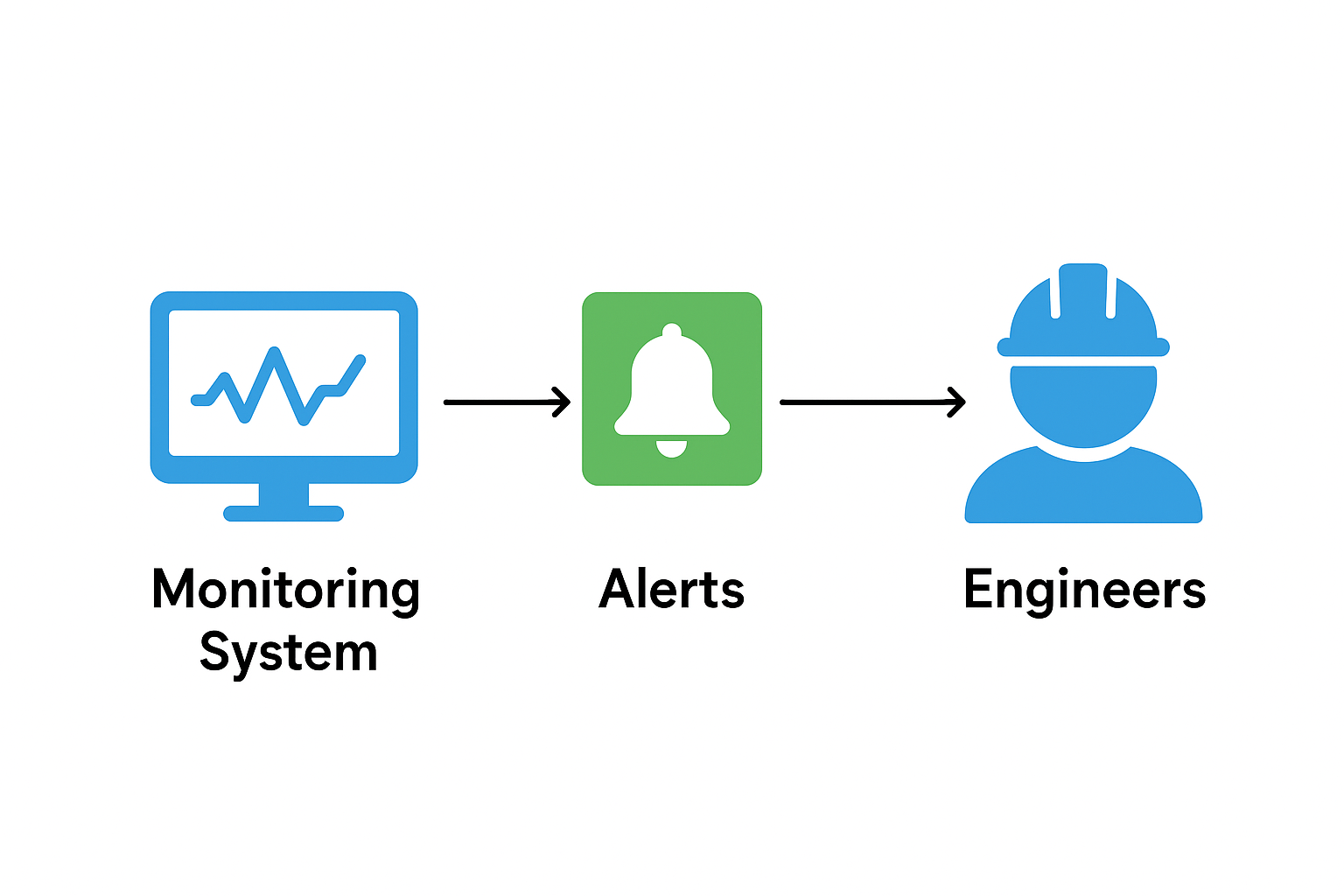
5. Monitoring & Alerting (crucial)
- Observe system health: CPU, memory, latency, error rates, and business metrics.
- Good monitoring reduces MTTD (Mean Time To Detect) and MTTR (Mean Time To Repair).
Examples: Datadog, Grafana, Prometheus, CloudWatch, ELK stack.
Benefits:
- Early detection of issues.
- Root cause analysis via logs.
- Prevents future failures.
Tip: Set intelligent alerts (thresholds + anomaly detection) to avoid alert fatigue.
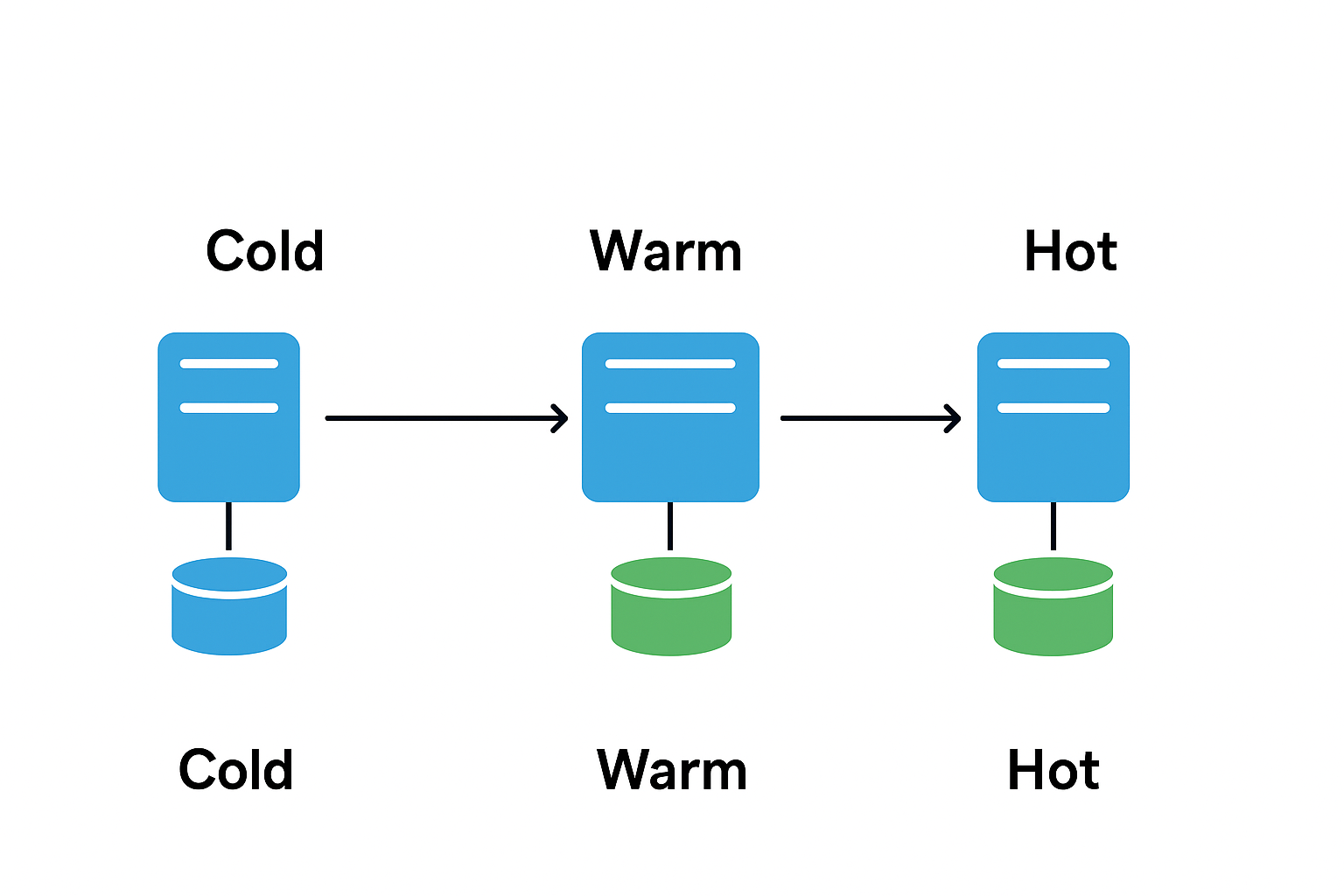
6. Disaster Recovery (DR)
- Prepare for major incidents — hardware failures, data centre loss, natural disasters.
DR approaches:
- Cold standby: Backups stored offsite; manual restore when needed (cheapest, slowest).
- Warm standby: Partial systems running in another region; scale up when needed.
- Hot standby: Fully mirrored system in another region for near-instant failover (fastest, costliest).
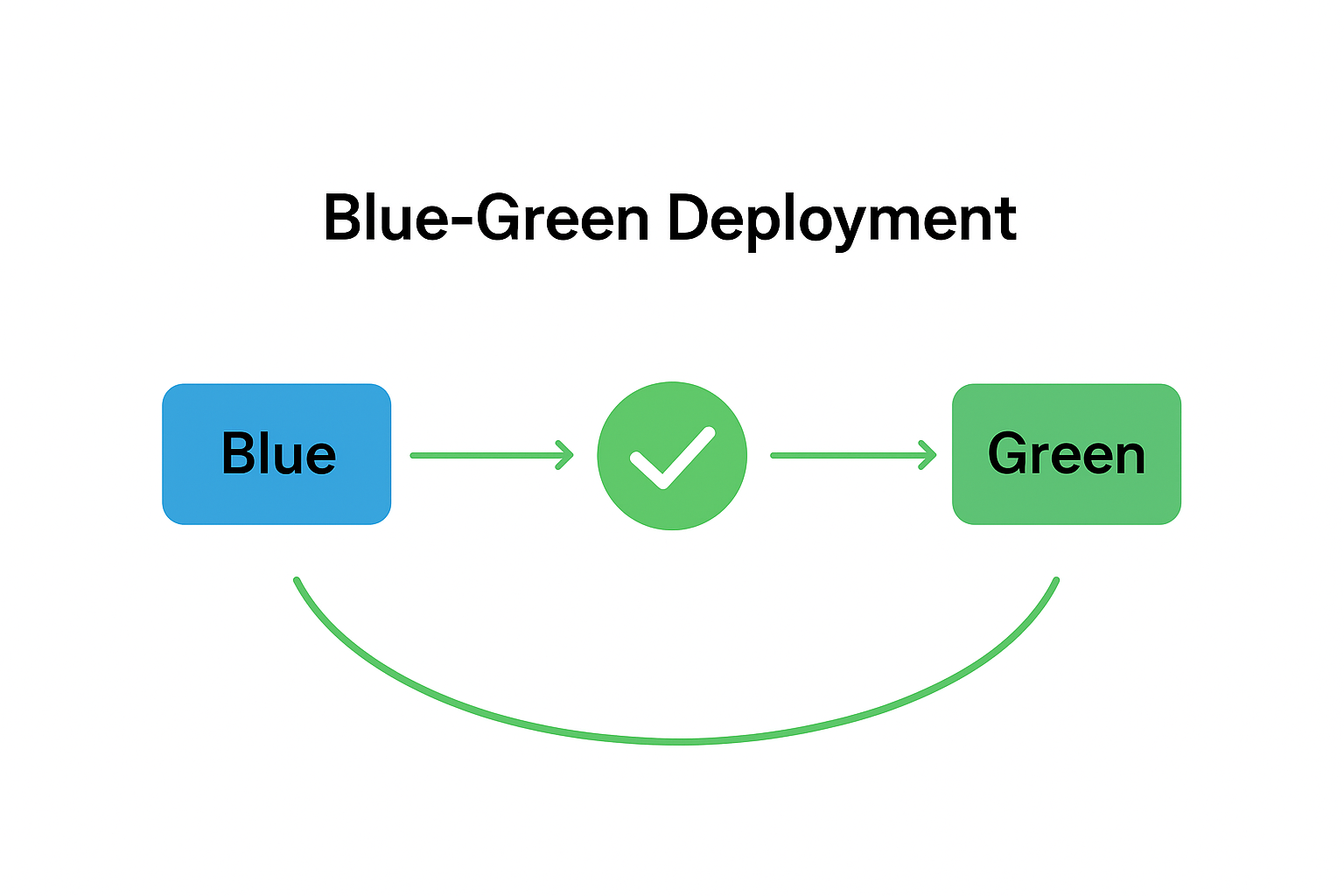
Planned vs Unplanned Downtime
Planned Downtime
- Scheduled activities: upgrades, schema changes, backups.
- Usually scheduled during off-peak hours to reduce impact.
- Mitigations: rolling updates, blue/green deployments, canary releases.
Unplanned Downtime
- Unexpected outages: hardware failure, software bugs, network issues, security incidents.
- Higher impact on user trust and revenue.
- Mitigations: redundancy, failover automation, quick recovery procedures, monitoring.
Putting It All Together — a short checklist
When designing for availability, use this checklist:
- Remove single points of failure across all layers.
- Put a load balancer in front of stateless app servers.
- Replicate data and ensure fast failover paths.
- Implement monitoring, alerts, and runbooks.
- Plan DR strategy (cold/warm/hot) based on RTO/RPO requirements.
- Automate deployments to minimize planned downtime.
Conclusion
Availability is a balance between cost, complexity, and business needs. Start by eliminating easy single points of failure, add monitoring, and iterate — measure the impact and raise your SLA target only when necessary.
High availability is not about eliminating downtime completely—that’s impossible. Instead, it’s about:
- Reducing both planned and unplanned downtime.
- Ensuring redundancy, failover, and monitoring.
- Designing systems that recover gracefully when failures happen.
The end goal: Users should barely notice failures.